
Cardiovascular diseases (CVDs) are like the ultimate party crashers, claiming the lives of 17.9 million people every year—that’s a whopping 31% of all deaths worldwide! Most of these are due to heart attacks and strokes, and what’s even scarier is that many victims are under 70. But what if we could see these crashers coming from a mile away? Enter machine learning: the superhero of the data world.
Machine learning models can dig through mountains of data to spot patterns and predict who might be at risk of heart disease. Think of them as your health fortune-tellers, using factors like high blood pressure, diabetes, and cholesterol levels to give you an early heads-up. With these models in action, we can catch potential heart problems before they turn into full-blown emergencies, helping to save lives and keep hearts happy.
In a previous post, we conducted Exploratory Data Analysis (EDA) of the Heart Disease Prediction Dataset and created a processed version of the dataset. In this post we will be training a machine learning model on this processed version of the dataset.
Dataset Overview
As we previously determined during our EDA, the dataset contains 918 samples, each characterized by 11 distinct features. The dataset is balanced and contains no missing values, eliminating the need for imputation, row deletion, or oversampling. We had to exclude RestingECG, RestingBP, and Cholesterol from our analysis as they do not contribute meaningful information for predicting heart disease.
df = pd.read_csv(Path.cwd() / "heart_processed.csv")
df.head()
| Age | Sex | ChestPain | FastingBS | MaxHR | ExerciseAngina | Oldpeak | ST_Slope | HeartDisease | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 40 | M | ATA | 0 | 172 | N | 0.0 | Up | 0 |
| 1 | 49 | F | NAP | 0 | 156 | N | 1.0 | Flat | 1 |
| 2 | 37 | M | ATA | 0 | 98 | N | 0.0 | Up | 0 |
| 3 | 48 | F | ASY | 0 | 108 | Y | 1.5 | Flat | 1 |
| 4 | 54 | M | NAP | 0 | 122 | N | 0.0 | Up | 0 |
Before we proceed, we need to encode our categorical features. Instead of using LabelEncoder, we’ll handle this process manually to ensure compatibility with our REST API (which we’ll develop in a future post 😝).
class Sex(IntEnum):
MALE = auto()
FEMALE = auto()
class ChestPain(IntEnum):
TYPICAL_ANGINA = auto()
ATYPICAL_ANGINA = auto()
NON_ANGINAL_PAIN = auto()
ASYMPTOMATIC = auto()
class StSlope(IntEnum):
UP = auto()
FLAT = auto()
DOWN = auto()
df['Sex'] = df['Sex'].map({'M': Sex.MALE, 'F': Sex.FEMALE})
df['ChestPain'] = df['ChestPain'].map({'ATA': ChestPain.ATYPICAL_ANGINA, 'NAP': ChestPain.NON_ANGINAL_PAIN, 'ASY': ChestPain.ASYMPTOMATIC, 'TA': ChestPain.TYPICAL_ANGINA})
df['ST_Slope'] = df['ST_Slope'].map({'Up': StSlope.UP, 'Flat': StSlope.FLAT, 'Down': StSlope.DOWN})
df['ExerciseAngina'] = df['ExerciseAngina'].map({'Y': True, 'N': False})
df.head()
| Age | Sex | ChestPain | FastingBS | MaxHR | ExerciseAngina | Oldpeak | ST_Slope | HeartDisease | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 40 | 1 | 2 | 0 | 172 | False | 0.0 | 1 | 0 |
| 1 | 49 | 2 | 3 | 0 | 156 | False | 1.0 | 2 | 1 |
| 2 | 37 | 1 | 2 | 0 | 98 | False | 0.0 | 1 | 0 |
| 3 | 48 | 2 | 4 | 0 | 108 | True | 1.5 | 2 | 1 |
| 4 | 54 | 1 | 3 | 0 | 122 | False | 0.0 | 1 | 0 |
Action Plan
Based on our exploratory data analysis (EDA), we have already drawn the following conclusions:
- We will employ OneHotEncoder to encode our categorical features.
- Numerical features are not normally distributed and contain outliers. To address this we will employ RobustScaler.
- We will only consider models that are robust to multicollinearity. Our candidate models will be
SVC,RandomForestClassifierandXGBoost.
class ModelChoice(IntEnum):
SVC = auto()
RANDOM_FOREST = auto()
XGB = auto()
def create_pipeline(model_choice: ModelChoice, random_state: int = RANDOM_SEED):
target_variable = "HeartDisease"
categorical_features = ["Sex", "ChestPain", "FastingBS", "ExerciseAngina", "ST_Slope"]
numerical_features = list(set(df.columns).difference([target_variable, "RestingBP", "Cholesterol", *categorical_features]))
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
numerical_transformer = Pipeline(steps=[
('scaler', RobustScaler())
])
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_features),
('cat', categorical_transformer, categorical_features)
])
if model_choice == ModelChoice.SVC:
model = SVC(random_state=random_state)
elif model_choice == ModelChoice.RANDOM_FOREST:
model = RandomForestClassifier(random_state=random_state)
elif model_choice == ModelChoice.XGB:
model = XGBClassifier(random_state=random_state)
else:
raise ValueError("Invalid model choice")
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', model)
])
return pipeline
Spiting our Dataset
We first need to split our dataset. We split the dataset into training and test sets to evaluate how well a model will perform on new, unseen data. The training set is used to teach the model, while the test set, helps assess its ability to generalize and make accurate predictions on unseen data. We’ll use the train_test_split function for this task. Specifically, we’ll allocate 80% of the data for training and reserve 20% for evaluation.
X, y = df.drop("HeartDisease", axis=1), df["HeartDisease"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=RANDOM_SEED)
Hyperparameter Tuning
We’ll use RandomizedSearchCV to identify a good set of hyperparameters for our model. Unlike regular parameters that the model learns during training, hyperparameters are set manually and control aspects of the learning process. Unlike GridSearchCV, which exhaustively tests all possible hyperparameter combinations, RandomizedSearchCV samples from the hyperparameter space at random. This approach can be more efficient and faster, especially when dealing with a large number of hyperparameters.
def hyperparameter_tuning(
model_choice: ModelChoice,
X: pd.DataFrame,
y: pd.Series,
param_distributions: dict,
random_state: int = RANDOM_SEED
) -> dict:
pipeline = create_pipeline(model_choice)
grid = RandomizedSearchCV(
pipeline,
param_distributions=param_distributions,
n_iter=100,
scoring='f1',
cv=5,
verbose=0,
random_state=random_state,
n_jobs=-1
)
return grid.fit(X, y).best_params_
param_dist = {
ModelChoice.SVC: {
'classifier__C': [0.1, 1, 10],
'classifier__kernel': ['rbf', 'sigmoid'],
'classifier__gamma': ['scale', 'auto'],
'classifier__class_weight': [None, 'balanced']
},
ModelChoice.RANDOM_FOREST: {
'classifier__n_estimators': [100, 200, 300, 400, 500],
'classifier__max_depth': [None, 10, 20, 30, 40, 50],
'classifier__min_samples_split': [2, 5, 10],
'classifier__min_samples_leaf': [1, 2, 4],
'classifier__bootstrap': [True, False]
},
ModelChoice.XGB: {
'classifier__n_estimators': [100, 200, 300, 400, 500],
'classifier__learning_rate': [0.01, 0.05, 0.1, 0.2, 0.3],
'classifier__max_depth': [3, 4, 5, 6, 7, 8],
'classifier__reg_alpha': [0, 0.1, 0.2, 0.3, 0.4],
'classifier__reg_lambda': [0, 0.1, 0.2, 0.3, 0.4]
}
}
best_params = {}
for model_choice in tqdm(ModelChoice):
params = hyperparameter_tuning(model_choice, X_train, y_train, param_dist[model_choice])
best_params[model_choice] = params
Evaluating our Model Candidates
To assess our model candidates, we’ll employ 5-fold cross-validation. During 5-fold cross-validation the data is split into five equal parts (or folds). The model is trained on four of these parts and tested on the remaining one. This process is repeated five times, each time using a different fold as the test set. The results from all five tests are then averaged to give a more accurate measure of the model’s performance. To this end we will be using cross_validate and employ accuracy, precision, recall, and F1 score as our metrics.
Accuracy measures overall correctness, Precision evaluates positive prediction quality, Recall assesses sensitivity to positive instances, and F1 Score balances Precision and Recall.
metrics = ['accuracy', 'precision', 'recall', 'f1']
results = {}
for model_choice in tqdm(ModelChoice):
model_name = model_choice.name.replace("_", " ")
if model_choice == ModelChoice.RANDOM_FOREST:
model_name = model_name.title()
results[model_name] = {}
pipeline = create_pipeline(model_choice, random_state=RANDOM_SEED)
pipeline = pipeline.set_params(**best_params[model_choice])
result = cross_validate(pipeline, X_train, y_train, cv=5, scoring=metrics)
for metric in metrics:
values = result[f'test_{metric}']
mean = values.mean()
std = values.std()
results[model_name][metric.title()] = f"{mean * 100:.3f} +/- {std * 100:.3f}"
pd.DataFrame(results).T
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| SVC | \( 86.918 \pm 1.480 \) | \( 85.830 \pm 2.698 \) | \( 91.269 \pm 1.139 \) | \( 88.427 \pm 1.053 \) |
| Random Forest | \( 86.916 \pm 2.117 \) | \( 85.661 \pm 3.010 \) | \( 91.519 \pm 1.240 \) | \( 88.460 \pm 1.653 \) |
| XGB | \( 86.106 \pm 2.732 \) | \( 85.889 \pm 2.574 \) | \( 89.287 \pm 2.969 \) | \( 87.536 \pm 2.432 \) |
In predicting heart disease, where missing a case can have serious consequences, we prioritize recall to ensure we catch as many cases as possible. Since XGBoost has the lowest recall, we’ve decided not to pursue it further. On the other hand, RandomForestClassifier offers the highest recall and has accuracy and F1 scores comparable to those of SVC.
Thus,
RandomForestClassifieremerges as the best choice for our model.
Testing our Model
Having decided on the best model, we’ll now test it on new data.
pipeline = create_pipeline(model_choice, random_state=RANDOM_SEED)
pipeline = pipeline.set_params(**best_params[model_choice])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
print(classification_report(y_test, y_pred))
precision recall f1-score support
0 0.75 0.86 0.80 77
1 0.89 0.79 0.84 107
accuracy 0.82 184
macro avg 0.82 0.83 0.82 184
weighted avg 0.83 0.82 0.82 184
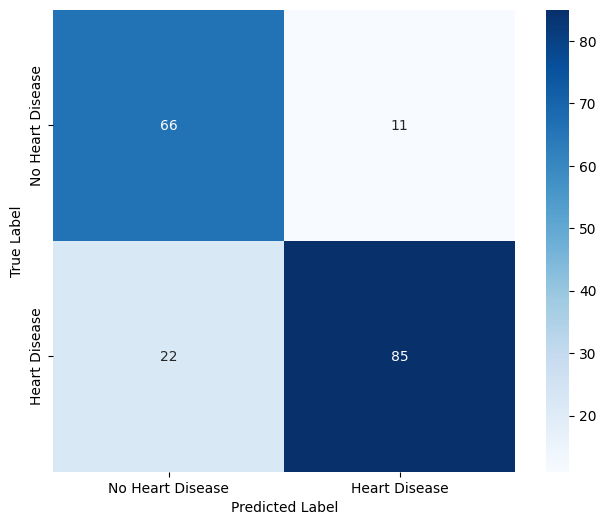
As shown from the classification report, our model performs well on new data, showing a good balance across evaluation metrics. The confusion matrix below confirms this, indicating that most samples are classified correctly with only a few false negatives.
plt.figure(figsize=(8, 6))
sns.heatmap(
confusion_matrix(y_test, y_pred), annot=True, fmt='d', cmap='Blues',
cbar=True, square=True,
xticklabels=['No Heart Disease', 'Heart Disease'],
yticklabels=['No Heart Disease', 'Heart Disease']
)
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()
Using Our Model
Our model can be used to make predictions with the following code:
payload = {
"Age": 20,
"Sex": Sex.MALE,
"ChestPain": ChestPain.ASYMPTOMATIC,
"FastingBS": True,
"MaxHR": 60,
"ExerciseAngina": True,
"Oldpeak": 0.0,
"ST_Slope": StSlope.DOWN,
}
pipeline.predict(pd.DataFrame([payload]))[0]
Finally, we can save our model using joblib for future use.
joblib.dump(pipeline, Path.cwd() / "model.joblib")
Stay tuned for our upcoming post, where we’ll dive into building a FastAPI backend for our model. Exciting developments are just around the corner! 🚀